Part 6: Token economics — the invisible cost of context
There are two ways developers discover that context is not free. The first is a surprising invoice at the end of the month. The second is a session that starts producing incoherent results — Claude ignoring a constraint it was given ten messages ago, or contradicting a decision it made five messages back.
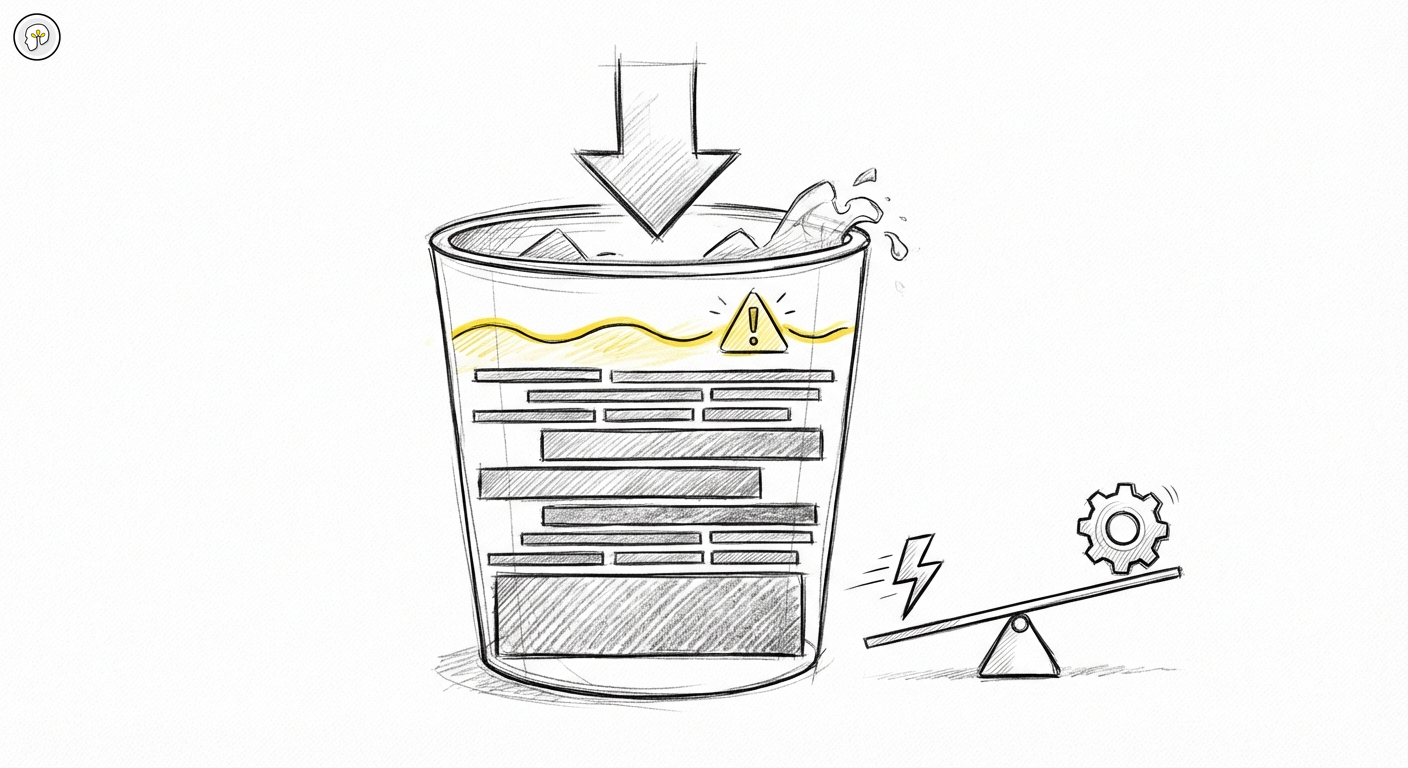
Both are the same problem from different angles: the context window has a size, a cost, and a degradation curve. Once you understand how tokens flow through a session, you can design sessions that stay efficient — and avoid the failure modes that appear when you do not.
What counts as tokens
Every interaction with Claude has a cost measured in tokens — roughly, fragments of words. One thousand English words is approximately 750 tokens. But what surprises most developers is not the cost of what they type. It is what else is included in every message.
System context is always present. Before your first message reaches the model, it is prefixed with the system prompt — which in Claude Code includes the tool definitions, the current session state, and your CLAUDE.md. Every. Single. Message.
Conversation history accumulates. Claude Code sends not just your latest message but the entire conversation history with every request. The response to message 30 in a session arrives with 29 prior exchanges attached. This is how Claude maintains coherence — it can refer back to earlier context. But it also means each message in a long session is more expensive than the same message sent fresh.
File reads add up. When Claude reads a file to understand context, that file content enters the context window. Reading ten large files is ten times more expensive than reading one. Large files read early in a session stay in the accumulated history for every subsequent message.
Tool outputs have size. When Claude runs a bash command and gets a thousand lines of log output, those thousand lines go into the context. Verbose tools are expensive tools.
How context accumulates — the compounding problem
The mechanics produce a compounding effect. Early in a session, messages are cheap: the history is short, the files read are few, the tool outputs are small. As the session extends, the payload attached to each message grows. By message 40 or 50 in a complex session, you may be paying for significantly more context than you intended — much of it from decisions and file reads that are no longer relevant to what you are currently doing.
This is not a flaw. It is how the model maintains coherence across a long session. The cost of that coherence is the growing context payload.
The practical implication is that a single long session for a large task is often more expensive than the same work done in shorter, scoped sessions. Breaking a large refactor into smaller focused sessions — each starting with fresh context — can cost less in aggregate than one session that accumulates everything.
Model selection as a cost and capability tradeoff
Claude Code lets you choose which model runs a given session. The choice is not arbitrary.
Larger models (like Opus) are more capable — they handle complex reasoning, nuanced architectural decisions, and tasks that require holding many considerations in mind simultaneously. They are also significantly more expensive per token.
Smaller models (like Sonnet) handle a very wide range of practical tasks equally well, at a fraction of the cost. Generating boilerplate, renaming variables, extracting interfaces, writing tests for already-defined behavior — these do not require the reasoning depth that justifies a larger model.
The practical rule: match the model to the actual reasoning requirement of the task.
A complex refactor that requires understanding the interaction between multiple subsystems — use the larger model. A batch of tasks that are essentially mechanical — file moves, comment cleanup, migration of a well-defined pattern — use the smaller model. The output quality difference is minimal; the cost difference is not.
The mistake developers make is treating model selection as a quality dial: "more is better." It is not. It is a specificity dial: match the tool to the task. Paying for Opus to generate a README template is waste. Skimping on Sonnet for an architectural debugging session is a false economy.
The CLAUDE.md cost
Part 3 of this series covered CLAUDE.md as the mechanism for encoding your judgment into every session. There is a cost dimension to add to that understanding.
CLAUDE.md is loaded as part of the system context on every single message. If your CLAUDE.md is 3,000 tokens — because it was built up over time with notes, reminders, examples, and context that felt useful at the time — every message in every session pays for those 3,000 tokens.
Over a heavy day of development, that adds up.
The discipline to apply: review your CLAUDE.md periodically and ask what is actually still load-bearing. Remove instructions that describe behavior Claude already exhibits by default. Remove notes that were relevant to one project but have been generalized. Remove examples that are redundant once the principle has been stated. Every word you cut from CLAUDE.md is a word you stop paying for on every message.
Lean CLAUDE.md is not just cleaner — it is cheaper.
Practical context hygiene
Use /clear strategically. The /clear command discards the accumulated conversation history. CLAUDE.md is still loaded fresh on the next message; you do not lose your project configuration. What you lose is the session history. Use /clear when a session has run long and you are starting a genuinely new task within the same project — not a continuation of the previous work, but a fresh problem. The fresh context is cheaper, and there is no coherence value in carrying forward a long history that is no longer relevant.
Compact mode (available in some interfaces) compresses the older parts of the conversation history into a summary, trading some detail for a significantly smaller context payload. Useful for very long sessions where you want to maintain continuity but cannot afford the full accumulated history.
Scope your tasks. The best context hygiene happens before the session starts. A well-scoped task — clear objective, limited file surface, specific output — produces a shorter session with a smaller peak context size than an open-ended exploration. Not every task can be tightly scoped, but the ones that can should be.
Watch tool verbosity. If Claude is running bash commands that produce large outputs and you are not using those outputs, they are still in the context. Prefer commands that produce focused output. If you need to inspect a large log, read the relevant section rather than the whole file.
Signs of context degradation
Context degradation is subtle. It does not announce itself. The model does not throw an error. What happens instead is a gradual erosion of coherence on the details established earlier in the session.
Common signs:
- Claude ignores a constraint that was clearly stated earlier. Not because it disagrees — it seems to have forgotten.
- Claude proposes an approach that contradicts a decision you made together three messages back.
- Responses start to feel generic — less tailored to the specific patterns and conventions of your codebase.
- Claude begins re-explaining things it already established, as if starting fresh.
When you see these signs, the session has likely grown beyond the effective context window. The fix is usually a fresh session, not a reminder. Sending "remember you decided X" adds more context to an already full window. Starting with /clear or a new session, and giving Claude the relevant prior decision as a fresh instruction, is more effective.
Subagents as context isolation
Part 4 of this series introduced subagents as a mechanism for parallel execution. There is a context dimension to add.
Each subagent runs in its own context window. When Claude Code spawns a subagent for a specific task, that subagent carries only the context relevant to its job: the system context, the specific instructions, the files it needs to read. It does not inherit the entire accumulated history of the parent session.
This is context isolation by architecture. A complex task broken into subagents — each handling one focused piece — produces a set of short, efficient contexts rather than one monolithic growing one. The aggregate token cost is often lower than a single session that tries to handle everything sequentially.
More importantly, the subagent results come back clean. Each one operated in a scoped context without the noise of earlier exchanges. The quality and coherence of the output reflects that.
The design implication: for large tasks, think about what can be delegated. Not just for parallelism — for cost efficiency and output quality through better context management.
Previous in this series: Part 5 — Permission modes
Capstone: Agentic code review: AI hunts the bugs. You still own the merge.