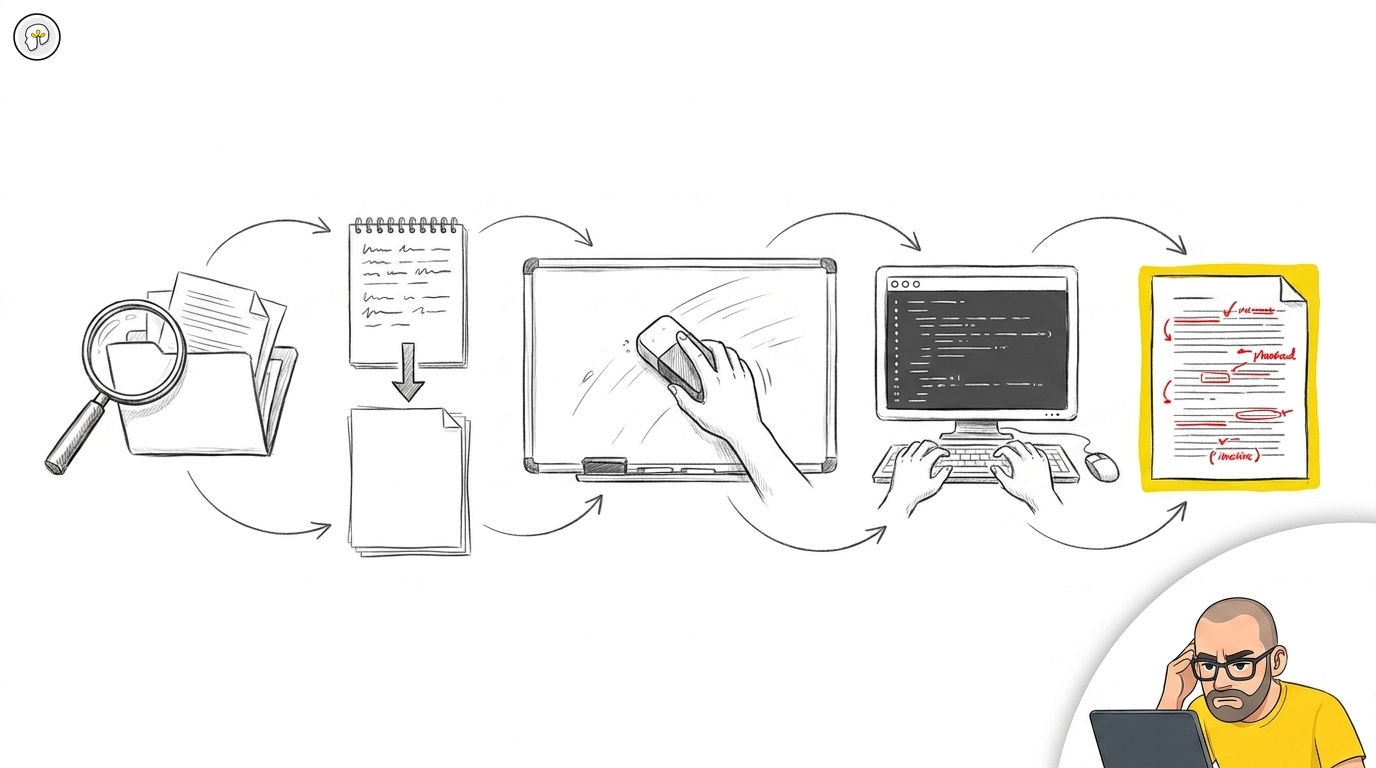
AI-utvecklingsflödet: läs, planera, töm, bygg, granska
De flesta utvecklare som använder AI-verktyg 2026 har ingen process. De öppnar en session, skriver en prompt, får ett resultat, itererar tills det ser rätt ut och committar. Ibland fungerar det. Ofta inte. När det inte gör det skyller de på verktyget.
Verktyget är sällan problemet. Processen är det.
Efter att ha arbetat med utvecklingsteam i flera organisationer — sett vad som fungerar och vad som fallerar i produktion, inte i demos — har ett arbetsflödesmönster visat sig vara konsekvent effektivt. Det är inte komplicerat. Det har fem steg. De flesta team hoppar över minst två av dem.
Loopen
Läs projektet → Planera till disk → Töm kontexten → Bygg från planen → Granska varje rad
Varje steg finns till av en specifik anledning. Hoppar man över något av dem försämras resultatet. Här är vad varje steg gör och varför det spelar roll.
Steg 1: Läs projektet
Varje session börjar likadant. Innan en enda rad kod genereras läser LLM:en projektet.
Inte "läser filen du jobbar i." Läser projektet. Arkitekturen. Den senaste git-historiken. Riktlinjerna och konventionerna. De befintliga mönstren. Domänterminologin.
En modell som förstår ditt system producerar kod som hör hemma i ditt system. En modell som inte gör det producerar syntaktiskt korrekt kod som bryter mot din arkitektur, använder fel namnkonventioner och introducerar mönster som krockar med allt runtomkring. Den koden kompilerar. Den klarar grundläggande tester. Och den skapar teknisk skuld i samma ögonblick den mergas.
Investeringen är fem minuter. Utbytet är timmar av undvikna fel i fel riktning.
Om ditt projekt har regelfiler — CLAUDE.md, AGENTS.md, .kilocode/rules/, .cursorrules — är det här steget där de gör nytta. Modellen läser dem och begränsar sig själv innan den producerar något. Utan regelfiler är Steg 1 kvalificerad gissning. Med dem är det informerad generering.
Steg 2: Planera till disk
Innan implementationen, be modellen ta fram en plan. Inte i konversationen — på disk.
Ett dokument för ändringsförfrågan. Ett designförslag. En specifikation. Vilket format som passar ditt projekt. Poängen är att planen blir en fil, committad eller åtminstone sparad, som existerar oberoende av konversationen.
Varför på disk? För att planen måste överleva nästa steg.
Det här motsvarar vad erfarna utvecklare alltid har gjort: tänka innan de kodar. Skillnaden med AI-verktyg är att tänkandet kan externaliseras — skrivas som ett dokument som både du och modellen kan referera till. En plan i konversationen är flyktig. En plan på disk är beständig.
Granska planen innan du går vidare. Det här är det billigaste stället att fånga upp en fel riktning. Att ändra en plan kostar minuter. Att ändra en implementation kostar timmar.
Steg 3: Töm kontexten
Det här är steget ingen gör. Det är det som förändrar allt.
När planen är skriven till disk — rensa konversationen. Starta en ny session. Eller, om verktyget stöder det, återställ kontextfönstret explicit.
Varför? För att kontextfönstret under planering är fyllt med utforskning, frågor, alternativ, återvändsgränder och beslutsartefakter. Den kontexten är värdefull för planering. Den är brus för implementation.
När du startar implementationsfasen med en ren kontext och bara laddar plandokumentet plus relevant kod, arbetar modellen från en tydlig specifikation — inte från en grumlig konversationshistorik som innehåller varje fel vägval från planeringsfasen.
Plandokumentet är bryggan mellan de två faserna. Det bär besluten framåt. Konversationsbruset stannar kvar.
Det här är inte en teoretisk optimering. Team som tömmer kontexten mellan planering och implementation rapporterar färre implementationer som missar målet, mindre "modellen gick i en annan riktning än vi diskuterade" och kortare granskningscykler. Planen på disk är entydig. Konversationen i minnet är det inte.
Steg 4: Bygg från planen
Ladda planen. Ladda relevant kod. Implementera.
Den här fasen är där de flesta tutorials börjar — och varför de flesta tutorials ger mediokra resultat. Implementation utan Steg 1–3 är att generera kod i ett vakuum. Implementation efter Steg 1–3 är att bygga inom förstådda begränsningar utifrån en granskad specifikation.
Modellen ska följa den godkända planen. Om något oförutsett dyker upp under implementationen — ett beroende som inte övervägdes, ett kantfall som planen missade — stoppa. Improvisera inte. Uppdatera planen först, fortsätt sedan. Planen är kontraktet mellan dig och verktyget. Att avvika från den utan att dokumentera avvikelsen är så "modellen gjorde något konstigt" uppstår.
Steg 5: Granska varje rad
Läs varje diff. Varje fil. Varje ändring.
Det här är ingen rekommendation. Det här är där det professionella ansvaret tar sig uttryck. Ögonblicket du läser en diff och beslutar att "det här är korrekt" är ögonblicket ansvarstagandet sker. Automatisera bort det — auto-commits, auto-changelogs, automatiserade testloopar som godkänner utan mänsklig granskning — och du automatiserar bort det enda som gör att ditt namn på koden betyder något.
Uppdatera changeloggen manuellt. Inte för att det tar lång tid. För att de två minuter det tar att skriva vad som ändrades tvingar dig att förstå vad som ändrades. En auto-genererad changelog är en sammanfattning av något ingen granskade. Den ser professionell ut. Den är meningslös.
Kör den verifiering som är relevant: tester, typkontroller, linting. Men verifiering är inte granskning. Verifiering bekräftar att kod kör. Granskning bekräftar att kod borde existera.
Varför den här ordningen spelar roll
De fem stegen är inte utbytbara. De bildar en beroendekedja:
Läs möjliggör informerad planering (utan det ignorerar planen det befintliga systemet). Planera externaliserar besluten (utan det lever besluten bara i konversationsminnet). Töm separerar planeringsbrus från implementationsklarhet (utan det hallucinerar modellen från inaktuell kontext). Bygg exekverar inom begränsningar (utan de tidigare stegen exekverar det i ett vakuum). Granska stänger ansvarsslingan (utan det är resultatet ägarslöst).
Hoppa över Läs och du får kod som inte passar systemet. Hoppa över Planera och du får kod som löser fel problem. Hoppa över Töm och du får kod som driver iväg från planen. Hoppa över Bygg-från-plan och du får improviserad kod. Hoppa över Granska och du får ägarslös kod.
De flesta team hoppar över Töm och Granska. Det är de två stegen som spelar störst roll.
Fördelen med röstinmatning
En praktisk förstärkning som multiplicerar arbetsflödets effekt: använd röstinmatning för planering.
När du talar en prompt istället för att skriva den uttrycker du mer kontext. Associationer, nyanser, villkor, kantfall — de flödar naturligt i tal men komprimeras bort vid skrivande. En talad beskrivning av vad som behöver ändras bär en informationstäthet som en skriven prompt sällan matchar.
Det här gäller specifikt Steg 1 och 2 — utforsknings- och planeringsfaserna där bredd av kontext spelar roll. För Steg 4 (implementation) är skrivna prompts med precisa instruktioner mer effektiva. Anpassa inmatningsläget efter fasen.
Vad det här arbetsflödet producerar
Team som konsekvent följer den här loopen rapporterar:
- Färre "modellen gick i fel riktning"-incidenter (planen fångar upp riktningsfel innan implementation)
- Kortare kodgranskningscykler (implementationen matchar specifikationen eftersom båda är explicita)
- Mindre teknisk skuld från AI-genererad kod (modellen arbetar inom inlästa riktlinjer, inte från generiska mönster)
- Högre förtroende för AI-assisterat resultat (varje rad är granskad, varje ändring är förstådd)
Inget av dessa utfall kräver en bättre modell, en dyrare prenumeration eller ett nytt verktyg. De kräver en process. Fem steg. Samma fem steg, varje gång.
Verktyget är kapabelt. Frågan är om du använder det inom en process som producerar ansvarsfullt resultat — eller utan en, i hopp om det bästa.
Det här arbetsflödet är den praktiska implementationen av principer som behandlas i Three ways to work with AI output och Why developer accountability can't be automated. För organisationslagret — repo-regler som begränsar AI innan den genererar — se From individual AI to organizational AI.