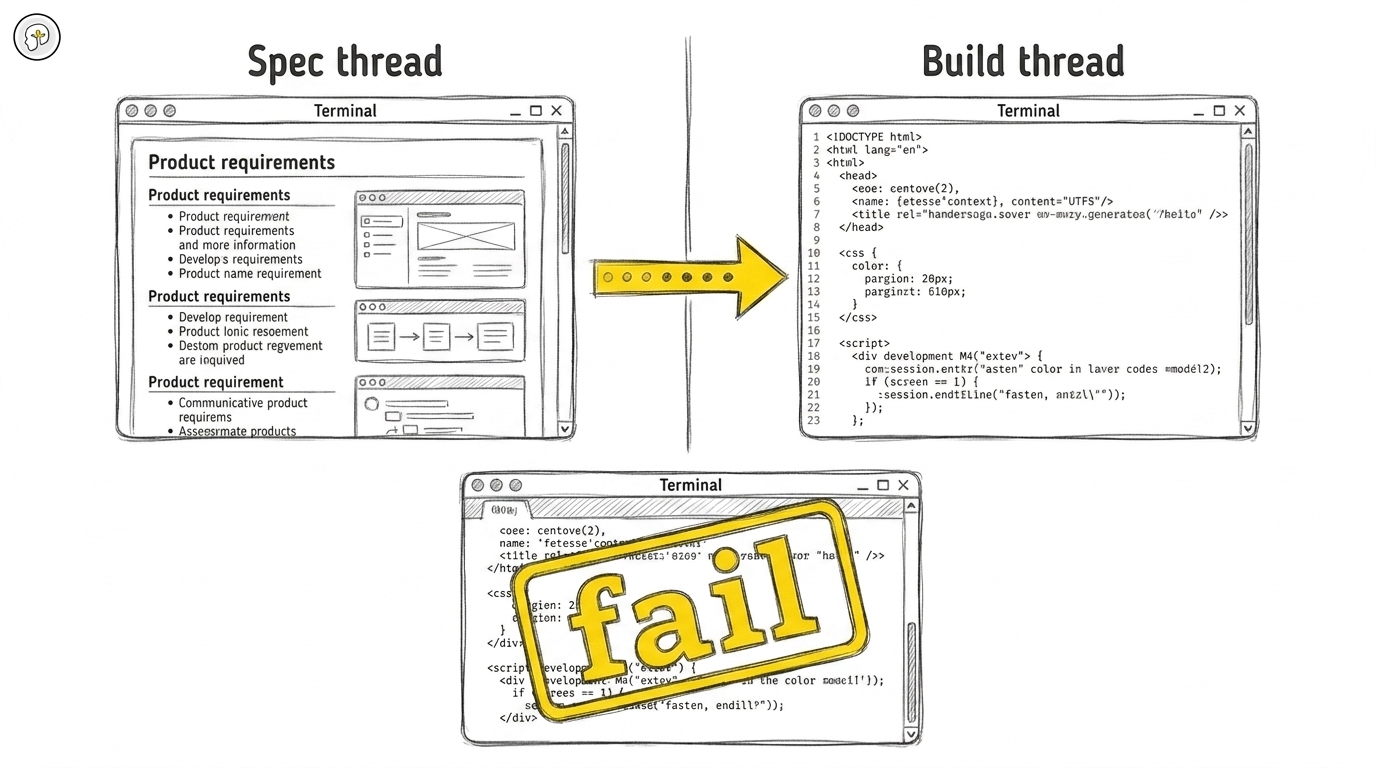
The two-thread pattern: Codex for spec, Claude for build
Two senior developers on the same team, working independently on the same task, used exactly the same AI workflow. They had never discussed it. They had never seen it documented. They both arrived at it through their own iteration.
The workflow:
- Open a thread with one model (Codex/GPT). Ask it to write a product-style specification.
- Refine the spec through dialogue until it captures the intent without specifying implementation.
- Close that thread. Open a new thread with a different model (Claude with a developer skill).
- Hand the spec over. Let the second model build from it.
- Optionally: hand the result back to the first model for cross-review.
They called it different things. The pattern is the same. I'm calling it the two-thread pattern.
It's becoming the team's de facto default.
Why two threads, not one
The temptation when working with AI is to keep the whole conversation in one place. One thread, one model, one history. Everything in context. Everything connected.
This fails for three reasons.
Context corruption. Long threads accumulate drift. The model "remembers" things that didn't quite happen — earlier turns subtly bias later ones. By the end of a 200-message conversation, the model is operating on a partly-fictional version of the project. The conversation feels coherent because the model is good at appearing coherent. But the output quality has degraded measurably from where it was at message 20.
Model affordances. Different models are good at different things. Codex/GPT has a strong product-thinking mode — it can write a specification that reads like it came from a product manager, which is useful precisely because product managers think about what and why before they think about how. Claude with a developer skill is exceptionally good at building from a well-formed spec, asking clarifying questions when the spec is ambiguous. The strengths are complementary in sequence, not in parallel.
Mixing providers breaks metadata. This is the most underappreciated failure mode. If you switch from Codex to Claude (or to Gemini) inside the same thread, the context window includes content from a model with different metadata expectations. The receiving model can read the content, but it can't read the conversation structure cleanly. Edge cases fire. Citation expectations break. Tool-use patterns get confused.
Two threads — separate, sequenced, with a deliberate handoff — avoids all three.
What each thread does
The spec thread, with Codex/GPT:
- Starts with the customer brief, the team's guidelines, and relevant code samples
- Produces a specification that's deliberately product-oriented, not implementation-oriented
- "Don't provide architectural alternatives. Don't provide implementation tutorials. Specify what the audit log should do and what it shouldn't do."
- Iterates until the spec captures intent without specifying mechanism
- Optionally: produces a README, a definition-of-done, and operations notes
- Saved to disk as a markdown file
The build thread, with Claude (typically with a developer skill):
- Starts fresh, with the spec from the previous thread loaded as input
- Reads the spec, asks clarifying questions, asks for permission to begin
- Builds incrementally with reviewable diffs
- Tests as it goes
- Handles ambiguity by surfacing it, not by guessing
The work loop runs inside the build thread. The spec thread is upstream of the work loop.
The cross-review variant
One of the senior developers added a step the other hadn't:
After Claude finished building, he opened a new thread with Codex and asked it to review what Claude had produced.
Codex found three issues that the developer-skill self-review had missed. One was a retry-after-first-batch failure in the queue handling. One was an access-control gap. One was a configuration edge case.
This works because models tend to catch each other's blind spots better than they catch their own. The retry logic was something Claude had written confidently because it followed Claude's training patterns; Codex evaluated it against different patterns and noticed the mismatch.
This isn't ensemble voting. It's adversarial review. Cheap, effective, and the most novel workflow technique I've seen this year.
Why this isn't ChatGPT 101
The two-thread pattern looks pedestrian. "Use one tool for one thing, another for another." That sounds like advice from 2023.
What's different:
The threads have a designed handoff. The spec produced in thread one is not a conversation snippet. It's a deliberate artifact: a markdown file on disk, structured like something a product manager would write. The handoff is to the file, not to the model. Either model could pick it up. The artifact survives the conversation.
The two-thread structure is upstream of model selection. Once you have the pattern, you can pick different models per thread depending on the task. Codex isn't the only product-style spec model. Claude isn't the only good builder. The pattern survives changes in which specific models you're using.
It explicitly forbids mixing within a thread. This is the part most developers haven't internalized yet. People still try to "just switch models" mid-conversation when something isn't working. That's not switching — that's silently breaking the context. If you want a different model, start a different thread.
When the pattern doesn't apply
- Throwaway work. A 20-line script doesn't need a spec phase. One thread is fine.
- Heavily exploratory work. Sometimes you don't know what you want until you've tried to build it. The spec emerges from the build attempt. In that case, expect to throw away the build and write a spec from what you learned.
- Solo work in your own domain. If you're deep in a codebase you know intimately, you can compress both phases mentally. The spec lives in your head; the build happens in one thread.
- When the project is too small to justify the overhead. A spec phase costs ~30 minutes. Below a 4-hour task, it's usually not worth it.
For real production work that spans more than a few hours, the two-thread pattern is paying for itself almost every time.
How to start using it
- Pick your next non-trivial task. Something with more than one architectural decision.
- Open a thread with Codex (or another model good at structured documents). Give it the customer brief, the code context, the guidelines. Ask it to write a product-style specification.
- Iterate on the spec, not the code. Push back when it specifies implementation. Ask for clarification when intent is unclear.
- Save the spec to disk. Markdown file. Commit it.
- Close the thread. Don't reuse it.
- Open a new thread with Claude (with a developer skill if you have one). Load the spec as input. Let Claude build.
- When Claude finishes, optionally open a Codex thread and ask for a code review.
You'll feel the difference in two places. The build phase is faster because the spec gives the model the right context up front. And the review surfaces issues you'd have missed otherwise.
The senior developers I see using this pattern are 4-5x as productive as the same developers were six months ago. Some of that is them. A lot of it is this.
The two-thread pattern was observed independently arrived at by two senior developers during a recent Mindtastic Sprint engagement, May 2026. The cross-review variant was added by one of them after reading research on cross-model evaluation. Customer identity withheld.