Voice on legacy code: talking away tech debt
Most teams point AI at greenfield — new features, fresh repos, fast prototypes. The hardest debt sits in the other direction: in the legacy systems that actually run the business and that nobody wants to touch. They work, they bill, and the documentation is either stale or missing. Everyone treats them as a black box with a sign on it: don't touch.
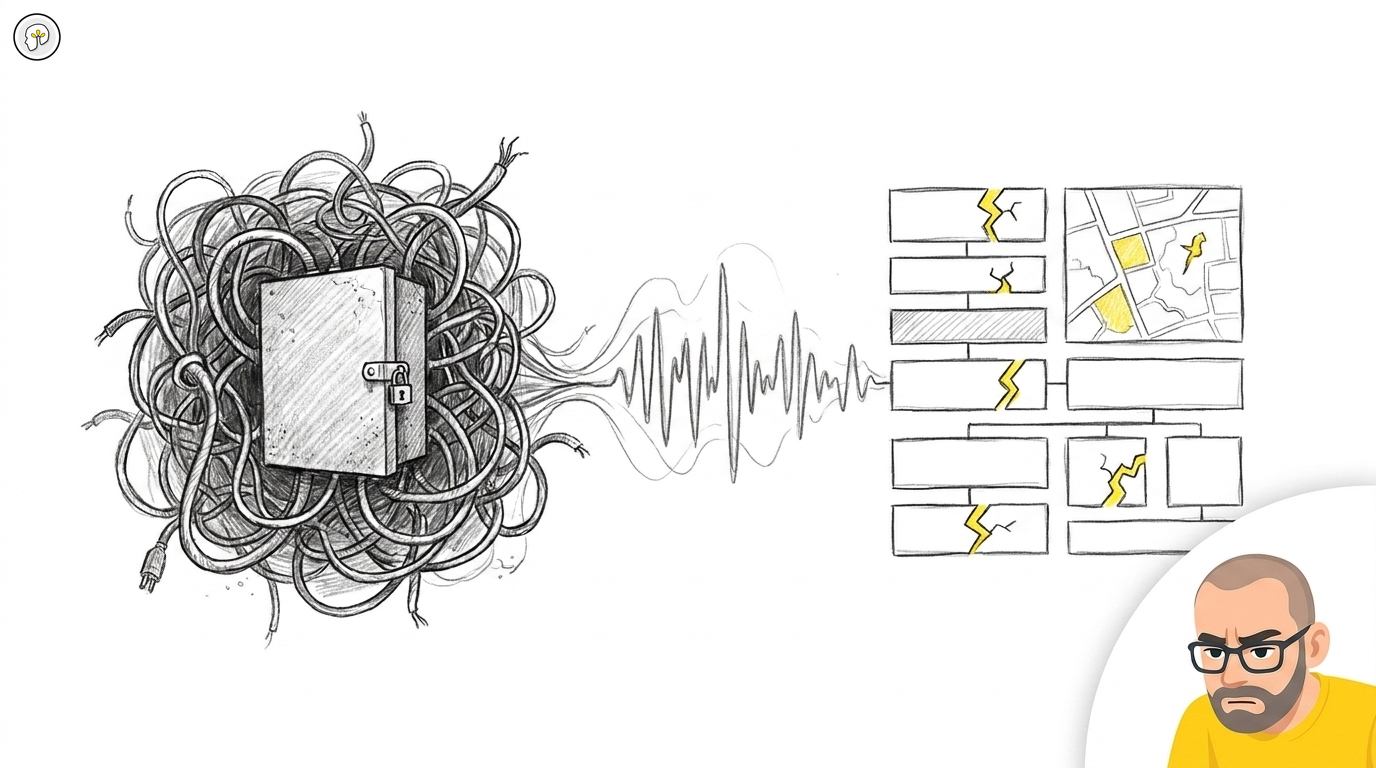
There's a way to use AI against those systems that almost nobody tries, and it's the least glamorous thing in the toolbox — have a developer talk through the code, out loud, while recording.
The method
Three steps, and none of them rewrite a line.
1. Record the walkthrough. Sit the developer who knows the system in front of a recording and have them narrate it. What does this do? Where does it break? What do you always check before you change it? What's the assumption buried in this function that nobody remembers? Developers aren't used to talking about their code — they write it. After a minute, it loosens.
2. Run the transcript against the codebase. This is where it gets useful. The transcript becomes structured text, and you put that next to the actual code. The model surfaces the diffs — where what the developer said the code does differs from what it actually does. It surfaces the documentation gaps, because now there's finally a description to compare against. It surfaces the spoken-in-passing assumptions the whole system rests on.
3. Produce the artifacts. Documentation that didn't exist. A map of where the debt actually lives. A list of the places where the developer's mental model and the code have drifted apart — which is exactly where the next incident is hiding.
You haven't refactored anything. But you've moved a real chunk of tech debt from nobody-knows to someone-knows — often around a fifth of it — using AI in the old process, not in a new build.
Why voice, specifically
The knowledge about a legacy system is rarely in the repo. It's in the head of whoever has lived with it: the 3 a.m. debugging, the times it broke, the quiet rules about what you don't touch. None of it is checked in anywhere.
A language model can only work with what's in the context window. The one thing a legacy codebase is missing is exactly what the developer carries around. Voice is the only practical way to get it out — ten minutes of talking holds more of the real model of the system than anyone will write down in a week.
The line you don't cross
The developer stays the owner of what's true. The model structures what was said and points at where it scrapes against the code. The developer decides what actually holds. This is not automated documentation that nobody signed off on — if no human owns it, it isn't documentation, it's a liability. The model surfaces; the human validates. That discipline is non-negotiable on a system people depend on.
It isn't new, and that's the point
This worked with transcription years ago. The technology was never the barrier. The barrier was that someone has to think to point the voice pipeline backward — at the old system — instead of only forward at the new build.
It's brown and boring and it doesn't demo well. That's probably why the debt is still sitting there.
Related: Voice to structured meeting documentation and The production reality gap.